Articles
| Name | Author |
|---|
Case Study: The power of XML – for dynamic operation manuals on EFBs at TUIfly
Author: Sebastian Franz, Referent Director, Flight Operations, TUIfly, and Klaus Fenchel, Managing Director, Ovidius
SubscribeThe power of XML – for dynamic operation manuals on EFBs at TUIfly

Sebastian Franz, referent director flight operations, at TUIfly, explains how the company deals with documentation.
Years ago, when flight operations involved paper folders that had to be updated once a week, I often had to search for bits of information page by page. When you’ve got nearly 900 pages, it can take quite a long time to get the information that is needed. Since then we have moved on to a ‘paperless cockpit’. To do that we had to optimize our information for all possible media and output devices… installed EFB, personal devices and the intranet on a standard web-browser; as well as having the ability to generate PDF and print-ready documents. It was also important that the publication process was automated.
TUIfly currently operates 38 Boeing 737-NG aircraft as a charter carrier for TUI Travel plc – a major European tour operator. Within the group we operate nearly 160 aircraft and we want to harmonize our operations and all our manuals, which has to be done across five different AOCs (Airline Operations Centers). This is why we have to think carefully about compilation and distribution of the material as well as adoption of new media channels by the end-users.
DOCUMENTATION IMPROVEMENTS
There have been many improvements in documentation from the days of the Ten Commandments (carved in stone), through hand written papyrus scrolls, to the printed bible. But perhaps we should first ask, what is documentation? Asking Siri on my iPhone, I got the definition of documentation (from Wikipedia) as “A set of documents provided on paper, or online, or on digital or analog media, such as audio tape or CDs. Examples are user guides, white papers, on-line help and quick-reference guides. It is becoming less common to see paper (hard-copy) documentation. Documentation is distributed via websites, software products, and other on-line applications.”
There are a number of requirements for modern documentation: It should be portable and available everywhere – and, as there are moves to reduce weight in aircraft, stones are not an option. Documentation should also be clearly structured and easy to navigate, something that is probably not achievable with scrolls. Moreover, it should be easily accessible and easy to maintain, and be updated automatically; I’m sure no-one wants to update their documentation manually.
Progress in the documentation industry is such that even the Encyclopedia Britannica is only available as an electronic application. The standard of today’s documentation is an electronic version of the former printed library.
Within our five airlines, we have taken the step of moving PDFs, which are essentially electronic pages, onto stylish devices. This does not fully harness the potential of e-documentation: it is essentially the same editorial process as with paper manuals whereby updates are electronic. The process of finding the information remains very much the same as with a paper manual. For us to fully harness the power of e-documentation we have to shift our mind-set. We need to listen to the priorities of our staff… priorities that include:
- All documents should be hyperlinked;
- They expect google-like search functions;
- Relevant changes should be automatically highlighted;
- It should be possible to add bookmarks and notes to personalize the manuals (much in the way that Post-it® notes were once used);
- Most importantly, it must be possible to filter the relevant content for a particular task.
OPEN YOUR MIND: NEW AGE DOCUMENTATION
In the ideal world, pilots want information to appear as it does in Wikipedia or Google. But what concept is needed and what data frame is able to handle those requirements? TUIFly GmbH embraced a new-age concept in the 80’s and has since never looked back. We adopted XML and manage our textual content with an XML based CMS (content management system). This technology allows us to have interlinked manuals which are based on one content structure which we can filter according to the task at hand. We can also already embed graphics and videos into the documentation as well as personalize our manuals which are updated automatically. Figure 1 nicely illustrates the features of our EFB application that runs on iPads and installed EFBs as well as our intranet.
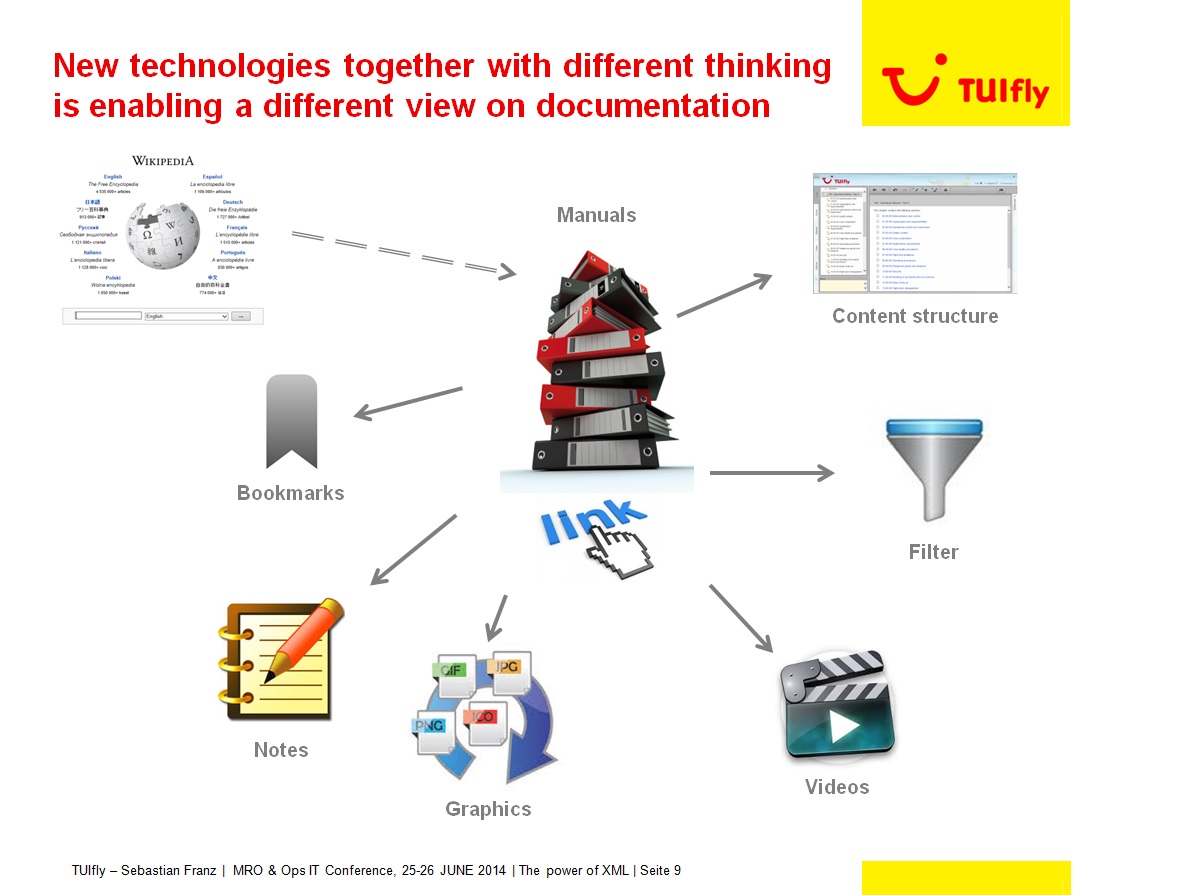
Figure 1: Linking all documentation in one structured system
Up until recently, progress has been slow with incremental improvements to the way that we manage our information; but now the benefits are starting to show. When I search, my device searches every piece of documentation available on my iPad and provides me with an immediate list of choices without me needing to page. In that way my documentation assists me in getting to the right place faster than a book with an index. If I search for a specific word, I have the benefit of it being highlighted within the text automatically so I always arrive in the right chapter with as little search time as possible. My updates are no longer packs of paper. As soon as I am in the vicinity of a Wi-Fi connection, my app checks for updates and downloads the new information. The revised information is then highlighted so that my attention is drawn to it immediately.
MANUAL HARMONIZATION
The TUI group wants to harmonize their operations including technical documentation as there can be massive savings there. It is possible to have one structure of information with the ability to reuse and repurpose content, thus decreasing the workload of the documentation department. With the power of XML these manuals and their creation can be harmonized, reducing redundancy and adding value. At the front-end where the pilots are the end users, we have the benefit of being able to filter according to the tail sign we are sitting in and receiving only the information that is relevant for that machine. Our documentation department can also then concentrate on creating more valuable content such as embedded 3-D graphics and info films to enrich the experience of e-documentation.
ADMINISTRATION DEMANDS
We mustn’t forget there are certain administrative expectations from the airline’s perspective when it comes to documentation. At TUIFly GmbH we identified that it should be centrally managed and administered; there should be a multi-airline capability (editorial system) so that we can reuse the same content in different chapters of the OM (operations manual) A/B/C/D. This should also allow the automated generation of revision records, including a list of effective chapters, and active changes; switching to a more modern style.
Airlines will demand additional output as PDFs, either the complete manual, or changes to the pack for revisions. The documents should be audit proof, e.g. linked compliance list, with no specific XML knowledge required. Finally, the system should deliver a cost-effective solution.
XML for flexible, powerful documents
Klaus Fenchel, managing director at Ovidius, discusses why XML, and not PDF or word processing formats, is the best document format for intelligent EFB applications.
Together with EasyBrowse — a 100% subsidiary company of Ovidius — we have a modular and integrated solution for content creation, content management, content publishing and content delivery: TCToolbox Airline Edition. TCToolbox is a generic XML CMS (content management system) which is in use in several industries where it supports authors and editors to reduce the complexity of and time needed for their documentation requirements. The companion product EB.4aviation is our system for electronic delivery to Windows and iOS based platforms.
Both systems are native XML systems — they harness the power of XML in an uninterrupted workflow. In addition EB.4aviatioin can also index and display many other document formats, e.g. PDF, Microsoft Word and Excel. This feature allows for a step-by-step migration from a non-XML workflow to a full XML based workflow.
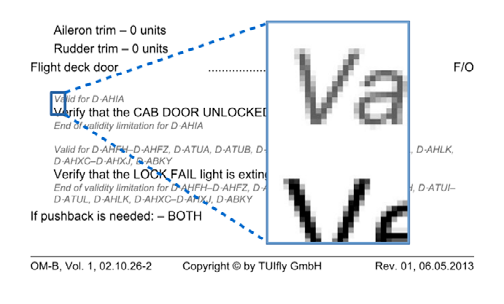
Figure 2: What is in a bitmap?
Figure 2 shows part of an OM-B page from TUIfly as a bitmap image. You as a human reader may well easily recognize that this is some kind of procedure. However, any software trying to process this document will not get very far. If you look closely you will just see dots on a page — there is no text, no graphics objects like lines or boxes.
Modification of the page is not really possible, but the format is very good for long-term archiving, as long as the images are saved as TIFs, or similar. Extracting higher level information like textual or structural content is very difficult from a bitmap — you have to use something like an Optical Character Recognition (OCR) system, or send it overseas for re-typing.
A PDF is already a step up in the information structure hierarchy. In many cases it is possible to identify words, lines, and with some additional processing intelligence you may even find paragraphs. However, frequently in a PDF, a text flow doesn’t exist. In essence, in a textual PDF you have characters which have an absolute position on a page, and some basic font information with a character. In general there is no structural information (there are tagged PDFs, but they are rare) or semantic structure, meaning you don’t know if something is a procedure or not. PDFs make interactive editing of content very difficult, and while content extraction is possible it is difficult, as is structure enrichment.
Word processing formats are suitable for easy interactive editing. In a word processing format there are paragraphs, tables and lists, graphics objects, cross references etc. which is an improvement on PDFs. It is possible to define named styles (e.g. Heading 1) which allows for uniform formatting of similar structural objects. Named styles may even carry some semantic information (e.g. by naming it ‘Warning’ instead of ‘Box1’) but there is a limit to what you can achieve with this mechanism. The benefit of word processing formats is that they are designed to allow easy interactive editing. Word processing formats are virtually useless for long-term archiving or for setting up stable and reliable documentation processes — even within one and the same word processing system 10 year old documents may not be compatible with today’s system. Extracting textual content from word processing formats is simple — automated extraction of the semantic information needed for intelligent applications like EFBs is difficult or impossible.
THE FUTURE IS XML
What exactly do we mean by ‘semantic’ information? Let us look at a screenshot (Figure 3) which displays the same piece of information we have seen already, now in an XML editor. There is the same textual information as in the word processing document and in the PDF, but there is an additional level of information: in XML we delimit ‘information objects’ with tags, e.g. an action consists of a challenge and a response, and, optionally, a crew member — the text is marked up accordingly. Procedure items consist of commands and steps etc. Each string of text not only carries textual information, it also says explicitly what it is. We call this ‘self-describing’: the text “Flight deck door” by its mark-up <Challenge> states that it is a challenge in a challenge response pair.
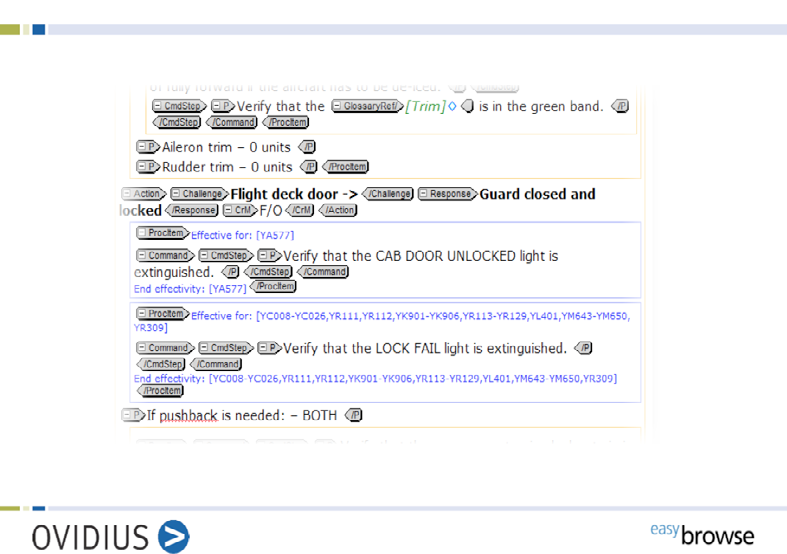
Figure 3: What is in an XML document
Additional information can be associated with information objects: we can assign effectivities to information objects: in Figure 3 one procedure item appears twice with a minor modification — the effectivity information codes which item applies to which aircraft. Other parameters which can influence the validity of information may be ‘target group’ (cabin, cockpit, maintenance), ‘temporal information’ (only valid on certain dates) etc. If information is marked up in such a way, the entire information body can easily be filtered based on these criteria. In essence, an XML document consists of textual content, text structures (like paragraphs, lists or tables) and highly semantic data islands (like procedures, actions, effectivities). An XML document therefore has both the characteristics of a textual document (easily readably by humans) and a database (easily processed by software for filtering, transforming and querying information).
THE INFORMATION STRUCTURE HIERARCHY
The formats discussed so far can be displayed in an information structure hierarchy.
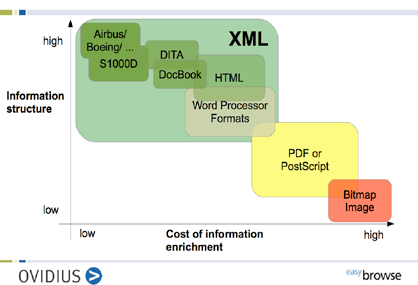
Figure 4: The information structure hierarchy
The horizontal axis in Figure 4 represents the cost for information enrichment from low to high, the vertical axis the level of information structure of the document format. Bitmaps, as we have seen, have virtually no information structure usable in automated processes — consequently enrichment in most cases is a manual process, associated with high costs. PDF is also low on the hierarchy.
XML is represented by a very large area. The reason is that XML, being a generic language for information description, can be used to describe almost any other type of format. As a matter of fact, modern word processor formats are XML based — this is true for Microsoft Word and OpenOffice. Still, they remain dedicated general purpose word processors with little to no support for encoding additional semantic information. The XML formats we are interested in can be found in the upper left corner, e.g. the XML structure of Boeing and Airbus documentation, the S1000D structures in defense documentation. These are the type of structures which allow us to create ‘intelligent data’ for ‘intelligent applications’.
Depending on which document formats you are using in your processes, several workflow scenarios are possible: let us briefly review two of these:
 Scenario 1 is when you get information from your pilots, engineers and other sponsors in a word processor format, PDF or mail, and the internal format of your operation manuals is also a word processor format. Based on this you distribute your manuals in print or as PDF; your EFB application is based also on PDF. In terms of software this is very inexpensive. However, you may have trouble meeting regulatory requirements, and the functionality of PDF based EFBs is low (filtering, re-flow of content for different device sizes, data driven connections to other applications etc.).
Scenario 1 is when you get information from your pilots, engineers and other sponsors in a word processor format, PDF or mail, and the internal format of your operation manuals is also a word processor format. Based on this you distribute your manuals in print or as PDF; your EFB application is based also on PDF. In terms of software this is very inexpensive. However, you may have trouble meeting regulatory requirements, and the functionality of PDF based EFBs is low (filtering, re-flow of content for different device sizes, data driven connections to other applications etc.).
Scenario 2 is the type of solution we are aiming at. We want to get input in XML, manage it in XML, and publish in XML. This process allows us to get the benefits we have seen. We can still generate PDF for printing and archiving in order to fulfill regulatory requirements but we also have the full functionality of XML-based EFB documentation applications. Implementing such a scenario has higher initial costs than scenario 1 and it requires a bit more training but the benefits easily compensate for these initial investments.
BENEFITS OF AN XML-BASED SYSTEM
If you want to create a PDF, you use the enriched XML to pre-filter for a specific fleet, run the type-setting automatically and then you publish. In the PDF, you’ll get automatic generation of LoeP/C (list of effective pages/chapters), LaC (list of actual changes), change marks, up-to-date glossaries and list of abbreviations which are consistent across all of your manuals.
For the EFB publication you always deliver the data unfiltered to all recipients; filtering occurs directly in the EFB application, e.g. by fleet, aircraft, target group etc. In addition, with an XML-based EFB format you can support device-optimized display and advanced functions like index-based searches, showing and hiding change marks, different styles for day and night mode, persistent commenting and bookmarking.
In an XML-based content management system you only change those information modules that need to be changed; all other parts of the manual remain untouched. Publication processes are fully automated and very quick. This leads to short update cycles. In addition you can easily generate differential updates — during the paper era they were called ‘change packs’, and you still can create these — but you can also deliver change packs to your EFB application, thus reducing the size of the updates you deliver to the display devices.
Finally, using a generic XML content management system you can replace parts of the system without having to touch the other parts — there is more flexibility in selecting system components, meaning there is less vendor lock-in.
CONCLUSION
A fully XML-based workflow for creating, managing, publishing and distributing your operation manuals has a number of consequences: There is definitely a learning curve in order to make the most of such an environment. The documentation process requires a certain level of expertise. Basic input can be delivered by all users in any format but you’ll need a small number of information experts that integrate and configure that input in order to be re-usable; they enrich it in order to allow filtering and efficient retrieval.
There may be higher initial costs for an XML-based system and the associated training, but there are definitely lower lifetime costs since you have shorter turn-around cycles and faster publication processes with little or no manual interaction. Working with such a system also helps to fulfil your regulatory requirements since you can always track who did what, when, and why. In some cases we reduced the times for preparing and carrying out audits from weeks to days.
If your information is important, and vital for your business, you need the right expertise to create, maintain and publish it. You will have pilots, crew members, and engineers, entering information at a level that is acceptable to them. But at the core, the people who configure the information, write the publications and automate the processes have to be experts. You don’t let amateurs service your aircraft: you shouldn’t let amateurs run your documentation processes.
And you should choose the only document format that is flexible and powerful enough to meet your requirements of today and tomorrow: XML.
Contributors’ details:
 Sebastian Franz, Referent Director, Flight Operations, TUIfly
Sebastian Franz, Referent Director, Flight Operations, TUIfly
Sebastian Franz has been with TUIfly since 2002 and is currently their Referent Director, Flight Operations. As First Officer on the B737, he was Quality Pilot & Auditor from 2005-2007 and has been Manager, Flight Operations for the past six years. Between 1997 and 2001, Sebastian combined the Lufthansa Flight Training School with academic studies, gaining his ATPL & University Degree (Dipl. Ing. Aviation Science & Management) in 2001. Since 2006, Sebastian’s extensive Project experience has covered “Paperless Cockpit”, “Electronic Flight Bag”, !iPad” and “Crew Request System”, with expertise in core processes and workflows within airlines. His
wide-ranging knowledge of EU-OPS, Regulations & Requirements and IASA regulations & Audits, together with a profound expertise in IT software and hardware, enables him to interface effectively with internal Departments and external Partners.
 Klaus Fenchel, Managing Director, Ovidius
Klaus Fenchel, Managing Director, Ovidius
Klaus Fenchel is the founder and managing director of the Berlin based Ovidius GmbH. He initiated the development of the core technologies that Ovidius uses as a basis for their products to this day. In the present day he is in charge of the strategic direction of the company as well as finance and personnel. After high school, he studied linguistics, computer sciences and mathematics at the Free University of Berlin. His studies took him to France (Rennes) and the USA (Cornell University and University of California, Santa Cruz). Following his university career he continued as a university lecturer specializing in linguistics, computational linguistics and programming. Later on he worked in various industrial companies as a language specialist and SGML/XML consultant and was the head of various software development projects. He founded Ovidius GmbH in 1996.
Comments (0)
There are currently no comments about this article.
To post a comment, please login or subscribe.